大家好,昨天完成了用one-hot coding表示屬性資料來訓練的模型,現在兩個模型都建立並且訓練完,今天就要來觀察這兩個模型訓練的結果,比較兩者的差異。
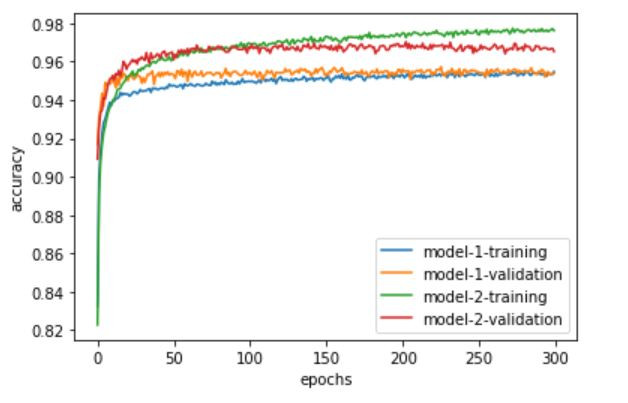
首先用兩個折線圖來觀察差異,一樣要先匯入matplotlib,然後分別繪製準確度與損失值的圖形,兩個圖形的x軸都表示訓練第幾次,y軸分別表示準確度以及損失值,都有四條線分別表示兩個模型的訓練以及驗證:
import matplotlib.pyplot as plt
plt.plot(history_1.history['binary_accuracy'], label='model-1-training')
plt.plot(history_1.history['val_binary_accuracy'], label='model-1-validation')
plt.plot(history_2.history['binary_accuracy'], label='model-2-training')
plt.plot(history_2.history['val_binary_accuracy'], label='model-2-validation')
plt.ylabel('accuracy')
plt.xlabel('epochs')
plt.legend()
plt.plot(history_1.history['loss'], label='model-1-training')
plt.plot(history_1.history['val_loss'], label='model-1-validation')
plt.plot(history_2.history['loss'], label='model-2-training')
plt.plot(history_2.history['val_loss'], label='model-2-validation')
plt.ylabel('loss')
plt.xlabel('epochs')
plt.legend()
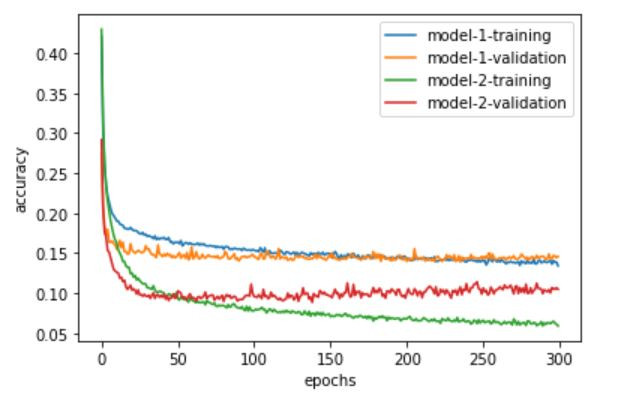
從上面兩個圖形可以看出,用one-hot coding表示屬性資料來訓練的模型明顯優於數值表示,在準確度的圖可以看出在訓練以及驗證都是one-hot coding表示大於數值表示,而損失值在訓練以及驗證都是one-hot coding表示小於數值表示。
接著用測試資料來觀察準確率:
model_1.load_weights(model_dir + '/Best-model-1.h5')
model_2.load_weights(model_dir + '/Best-model-2.h5')
loss_1, accuracy_1 = model_1.evaluate(x_test_normal, y_test)
loss_2, accuracy_2 = model_2.evaluate(x_test_one_hot, y_test)
print("Model-1: {}%\nModel-2: {}%".format(accuracy_1, accuracy_2))
結果顯示用數值表示的確度率大約為0.9486%,用one-hot coding表示的準確率大約為0.9632%,也是用one-hot coding表示的優於數值表示。

